Reagents and raw materials for monoclonal antibodies
- Type of document
- Brochure
- Language
- en
| PRODUCT CODE | PRODUCT NAME | CAS NUMBER |
| A9778 | ECOSURF™ EH-9 (Triton X-100 replacement) |
64366-70-7 |
| A9779 | ECOSURF™ SA-9 (Triton X-100 replacement) |
|
| A9780 | TERGITOL™ 15-S-9 (Triton X-100 replacement) |
68131-40-8 |
The original, Triton X-100 has been classified as a high risk substance due to the REACH regulation and can no longer be sold easily.
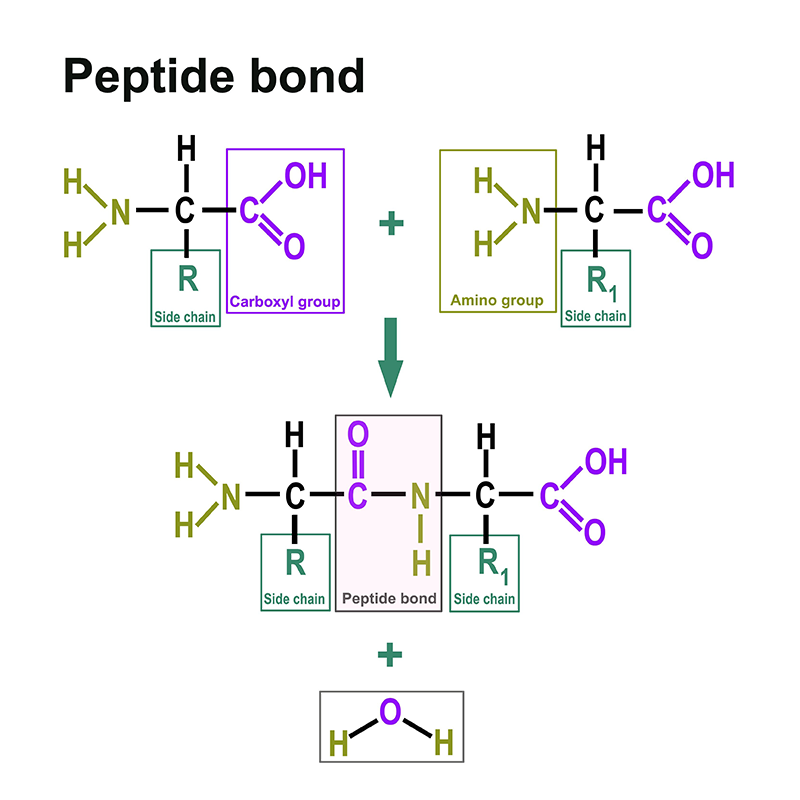
The techniques of protein biochemistry are not only used to determine the natural states of proteins, but also to produce desired proteins by means of targeted manipulations. So-called expression systems are used for this purpose. One of the best known is the Lac-operon. Here, the genes for certain proteins are assembled by molecular biology using this operon. In bacteria (E. coli), the organism then produces the proteins. The whole process is induced by the substance isopropyl-β-D-thiogalactopyranoside (IPTG). We have a selection of IPTG available for our customers.
| PRODUCT CODE | PRODUCT NAME | CAS NUMBER |
| A1008 | IPTG BioChemica | 367-93-1 |
| A4773 | IPTG for molecular biology, dioxane free | 367-93-1 |
| A7211 | IPTG from plant origin galactose, dioxane free | 367-93-1 |
The biggest opponent of a protein is ... another protein. The degradation is catalyzed by proteases. These are found in all organisms and therefore often also in the samples of users/scientists. Since it would often be uneconomical to achieve a direct separation, so-called inhibitors are used. These interfere with the catalytic activity of the proteases so that they cannot become active and other enzymes remain intact.
Sometimes, however, it is precisely the protein degradation that is desired. For example, if one only wants to examine the nucleic acids in a sample. The proteins can then be interfering. A well-known example might be certain test kits for COVID-19. Proteinase K is a protease that catalyzes the degradation of proteins. We offer high quality Proteinase K in lyophilized and already dissolved ready-to-use form.
Other important products that are used are albumins and co-factors such as NAD and NADPH. They may be needed as stabilizers or as coenzymes in various reactions.
The field of proteomics will remain exciting for a very long time. It shows us the true actual state of each cell. Many assays will still lead to some groundbreaking discoveries here.
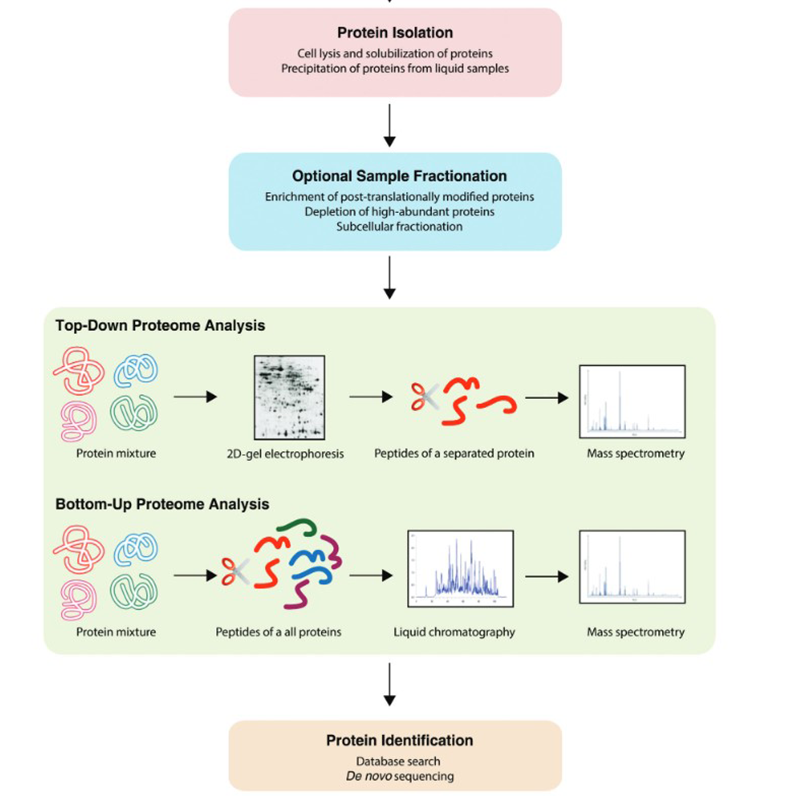
In addition to the techniques already mentioned above, a variety of workflows can be found in the field of proteomics. These can take place botton-up or top-down:
.png)
| PRODUCT CODE | PRODUCT NAME | CAS NUMBER |
| A1088 | ABTS® BioChemica | 30931-67-0 |
| A4983 | Acrylamide solution (30%) - Mix 29 : 1 for molecular biology | |
| A3626 | Acrylamide solution (30%) - Mix 37.5 : 1 for molecular biology | |
| A3658 | Acrylamide solution (40%) - Mix 19 : 1 for molecular biology | |
| A0385 | Acrylamide solution (40%) - Mix 29 : 1 for molecular biology | |
| A4989 | Acrylamide solution (40%) - Mix 37.5 : 1 for molecular biology | |
| A7582 | Acrylamide 2K solution (18%) for denaturing DNA-PAGE | |
| A7590 | Acrylamide 2K solution (8%) for denaturing DNA-PAGE | |
| A1089 | Acrylamide 2K Standard grade, extrapure | 79-06-1 |
| A0951 | Acrylamide 4K solution (30%) - Mix 29 : 1 | |
| A1672 | Acrylamide 4K solution (30%) - Mix 37.5:1 | |
| A1577 | Acrylamide 4K solution (40%) - Mix 37.5:1 | |
| A1090 | Acrylamide 4K ultrapure | 79-06-1 |
| A1421 | AEBSF Hydrochloride BioChemica | 30827-99-7 |
| A0850 | Albumin (BSA) EIA and RIA grade | 9048-46-8 |
| A2244 | Albumin (BSA) Fraction V (pH 5.2) | 9048-46-8 |
| A1391 | Albumin (BSA) Fraction V (pH 7.0) | 9048-46-8 |
| A6588 | Albumin (BSA) Fraction V (pH 7.0) for Western blotting | 9048-46-8 |
| A4344 | Albumin crude from chicken egg white | 9006-59-1 |
| A1523 | 4-Aminoantipyrine BioChemica | 83-07-8 |
| A7708 | AppliCoat Plate Stabilizer | |
| A2132 | Aprotinin BioChemica | 9087-70-1 |
| A2568 | Avidin BioChemica | 1405-69-2 |
| A1117 | BCIP BioChemica | 6578-06-9 |
| A3636 | Bisacrylamide for molecular biology | 110-26-9 |
| A3417 | CheLuminate-HRP PicoDetect | |
| A2144 | Chymostatin | 9076-44-2 |
| A1101 | DTT BioChemica | 3483-12-3 |
| A2948 | DTT for molecular biology | 3483-12-3 |
| A3668 | DTT solution 1 mol/L (1 M) for molecular biology | 3483-12-3 |
| A1007 | X-Gal BioChemica | 7240-90-6 |
| A4978 | X-Gal for molecular biology | 7240-90-6 |
| A2243 | L-Glutathione oxidized BioChemica | 27025-41-8 |
| A9782 | L-Glutathione reduced (USP) pure, pharma grade | 70-18-8 |
| A2084 | L-Glutathione reduced BioChemica | 70-18-8 |
| A1008 | IPTG BioChemica | 367-93-1 |
| A4773 | IPTG for molecular biology, dioxane free | 367-93-1 |
| A7211 | IPTG from plant origin galactose, dioxane free | 367-93-1 |
| A2185 | Luminol | 521-31-3 |
| A1108 | β-Mercaptoethanol for molecular biology | 60-24-2 |
| A1243 | NBT BioChemica | 298-83-9 |
| A1272 | 2-Nitrophenyl-β-D-Galactopyranoside BioChemica | 369-07-3 |
| A1028 | 4-Nitrophenyl-β-D-Glucuronide BioChemica | 10344-94-2 |
| A0830 | Nonfat dried milk powder | |
| A2205 | Pepstatin A | 26305-03-3 |
| A0999 | PMSF BioChemica | 329-98-6 |
| A2935 | Ponceau S - Solution | |
| A8889 | Protein Marker VI (10 - 245) prestained | |
| A1495 | Streptavidin ultrapure | 9013-20-1 |
| A1148 | TEMED | 110-18-9 |
| A3840 | 3,3',5,5'-Tetramethylbenzidine BioChemica | 54827-17-7 |
| A1828 | Trypsin inhibitor from soybean > 7000 BAEE | 9035-81-8 |